Okay, so today I’m gonna walk you through this little project I tackled – a Bangladesh address formatter. Nothing fancy, but it was a fun exercise and I learned a thing or two.
It all started when I was messing around with some e-commerce data. A lot of the addresses were just… a mess. Different formats, typos galore, missing info – you name it. Since I’m dealing with customers in Bangladesh, I figured, why not build something to standardize these addresses?
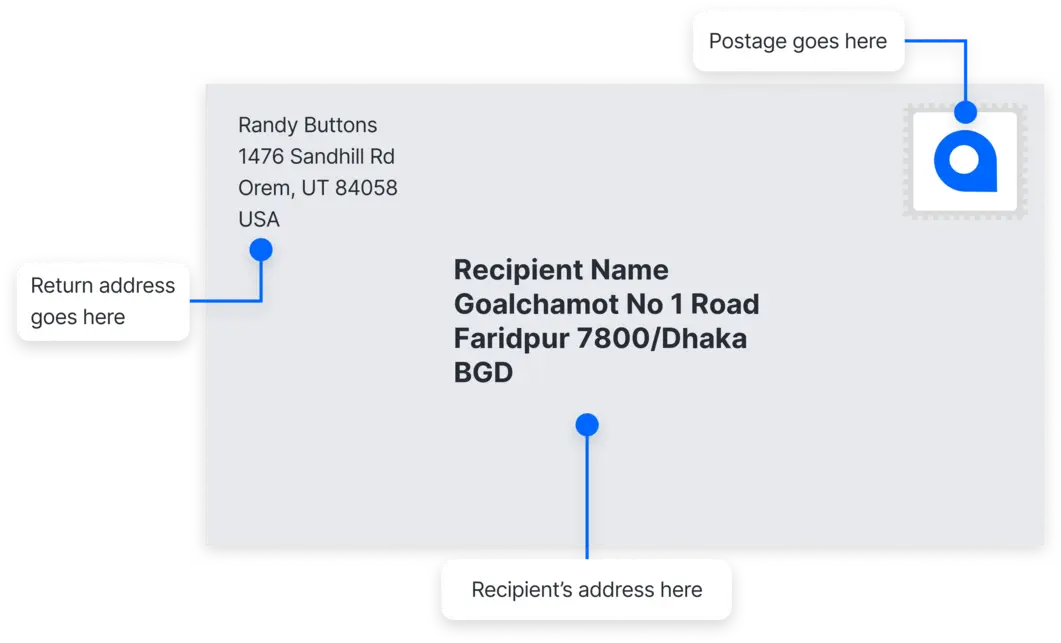
First things first, I did some research. I needed to figure out the actual structure of a proper Bangladesh address. Turns out, there’s a generally accepted format, but it’s not always followed consistently. I found some examples online, government websites, stuff like that. Basically, I pieced together this order:
House Number and Street Name (or Village)
Post Office Name
Upazila/Thana (Sub-district)
District
Postal Code
Bangladesh
So, I fired up my trusty code editor. I decided to go with Python for this – seemed like the easiest route. My initial idea was to break down the address into chunks and then reassemble it in the correct order.
I started with a simple function that took an address string as input. My first hurdle? Cleaning the input. Addresses are usually full of extra spaces, weird characters, and inconsistent capitalization. So, I wrote some code to:
Remove leading/trailing whitespace.
Convert the entire address to lowercase (to handle capitalization issues).
Remove any non-alphanumeric characters (except spaces, commas, and hyphens).
Next, I needed to somehow identify the different parts of the address. This was the tricky bit. I initially tried to use regular expressions, but Bangladesh is a bit different. See, other places may have well defined rules, but Bangladesh has a wide range of addressing styles even inside it.
My current approach? To build a rules-based formatter that can be customized with ease. I began by creating a json config file that consists of regular expression matching and corresponding keys in the result. For example:
"regex": "b(dhakadhaka city)b",
"key": "district"
"regex": "b(gulshan)b",
"key": "upazila"
This means, given an input address, each of the items will be applied. This is very powerful if you want to be very specific about different areas and styles, but it can be very slow if you have a large number of rules defined. It’s important to profile performance to ensure addresses are processed as quickly as possible.
Once I had the key parts identified (or at least, attempted to identify them), I started reconstructing the address. I used the format I mentioned earlier, making sure to add commas and newline characters for readability.
Of course, it wasn’t perfect. There were (and still are) edge cases and weird address formats that my code couldn’t handle. But it was a start. I tested it with a bunch of sample addresses, tweaking the code and regular expressions until I got a decent level of accuracy.
What I learned:
Address parsing is HARD. Especially when you’re dealing with user-generated data.
Regular expressions are powerful, but they can quickly become a nightmare to maintain.
Having a well-defined address format is crucial for data quality.
Next steps:
I want to improve the accuracy of the address parsing, maybe by using some machine learning techniques.
I need to handle missing address information more gracefully.
I’d like to integrate this into a larger data processing pipeline.
All in all, it was a fun project. It’s not perfect, but it’s a step in the right direction. And who knows, maybe it’ll help someone else who’s struggling with messy Bangladesh addresses.










{kind=link}